Confusion Matrix: The two types…
Understanding Confusion Matrix
A confusion matrix is a table that is often used to describe the performance of a classification model (or “classifier”) on a set of test data for which the true values are known. Classification Models have multiple categorical outputs. Most error measures will calculate the total error in our model, but we cannot find individual instances of errors in our model. The model might misclassify some categories more than others, but we cannot see this using a standard accuracy measure.

Furthermore, suppose there is a significant class imbalance in the given data. In that case, i.e., a class has more instances of data than the other classes, a model might predict the majority class for all cases and have a high accuracy score; when it is not predicting the minority classes. This is where confusion matrices are useful.
A confusion matrix presents a table layout of the different outcomes of the prediction and results of a classification problem and helps visualize its outcomes. It plots a table of all the predicted and actual values of a classifier.
The basic layout of the matrix:
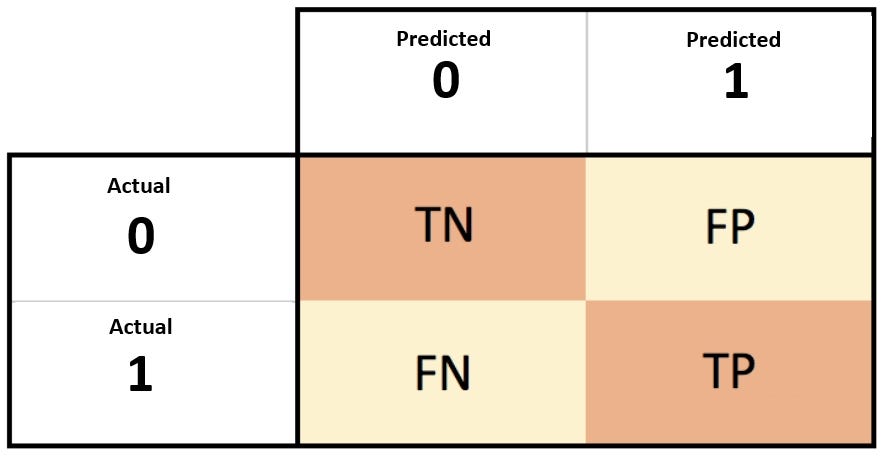
We can obtain four different combinations from the predicted and actual values of a classifier:
- True Positive(TP): The number of times our actual positive values are equal to the predicted positive. You predicted a positive value, and it is correct.
- False Positive(FP): The number of times our model wrongly predicts negative values as positives. You predicted a negative value, and it is actually positive.
- True Negative(TN): The number of times our actual negative values are equal to predicted negative values. You predicted a negative value, and it is actually negative.
- False Negative(FN): The number of times our model wrongly predicts negative values as positives. You predicted a negative value, and it is actually positive.
Finding the accuracy of our model:
To find how accurate our model is, we use the following metrics:
- Precision: Precision is used to calculate the model’s ability to classify positive values correctly. It is the true positives divided by the total number of predicted positive values.
The formula for Precision is TP / (TP + FN)
- Accuracy: Accuracy is used to find the portion of correctly classified values. It tells us how often our classifier is right. It is the sum of all true values divided by total values.
The formula for Accuracy is (TP+TN)/ (TP+TN+FP+FN)
- Recall: It is used to calculate the model’s ability to predict positive values. It is the true positives divided by the total number of actual positive values.
The formula for Recall is TP/ (TP+FN)
- F1-Score: It is the harmonic mean of Recall and Precision. It is useful when you need to take both Precision and Recall into account.
The formula for F1-Score is 2*Precision*Recall/ (Precision+Recall).
The 2 types of error:
False Positive (FP) — Type 1 error
- The predicted value was falsely predicted
- The actual value was negative but the model predicted a positive value
- Also known as the Type 1 error
False Negative (FN) — Type 2 error
- The predicted value was falsely predicted
- The actual value was positive but the model predicted a negative value
- Also known as the Type 2 error
Cyber Crime and Confusion Matrix:
Cybercrime has become an all-too-familiar topic in today’s global headlines.
It’s clear that along with its multitude of benefits, the introduction of new technologies gives attackers opportunities to develop new and easier methods for infiltrating data systems to steal sensitive information.
This isn’t a new phenomenon. In fact, it goes back not just decades but centuries.
Technically, the first cyberattack happened in France well before the internet was even invented, in 1834. Attackers stole financial market information by accessing the French Telegraph system. From that moment on, cybercrime has grown exponentially, marked by an intriguing history of tactics, techniques, and procedures — all implemented for malicious gain.


The advanced technology used for cybersecurity — including machine-learning and AI tools — are employed by today’s cybercriminals too. So, staying one step ahead of them is an ongoing challenge.
Preparing for the next generation of cybercrime requires users to become vigilant about which types of attacks are in the wild — and clearly understand how to defend themselves against these threats.
Successful approaches to cybersecurity will include multi-prong defenses. And it will involve service providers and third-party expertise even for organizations large enough to employ comprehensive cybersecurity technology and expert staff in-house. What every organization needs to battle cybercrime today, as well as tomorrow, is a security operations center.
I would like to thank the reader of this article to set aside a sliver of your valuable time and gaining some knowledge about the topics discussed here.
Feel free to ask any queries. Don’t forget to share this article with your fellow acquaintances. Connect with me on LinkedIn using the link provided below:








